A Research Framework for the Skill Nobody Can Name, the Market Nobody Can Price, and the Power Nobody Can See Consider the concept of orchestration class.
By Tyler Maddox | February 14, 2026
The narrative of the AI age has a gap in it. Not a small one. A structural one.
Yesterday, Microsoft AI chief Mustafa Suleyman declared that “most, if not all, professional tasks” for lawyers, accountants, project managers, and marketing professionals “will be fully automated by AI within the next 12 to 18 months.” Two weeks earlier, Anthropic CEO Dario Amodei warned that AI could eliminate 50% of entry-level white-collar jobs and trigger unemployment of 10–20% within one to five years.
Capital owns the models. The models are eating the professions. So far, the story tracks.
But here is what neither Suleyman nor Amodei addresses: who governs the transition?
Not “who writes policy.” Not “who gives speeches at Davos.” Who actually sits between the models and the outcomes? Who designs the agent architectures, interprets the ambiguous goals, debugs the cascading failures, and decides which outputs are trustworthy and which are hallucinated garbage?
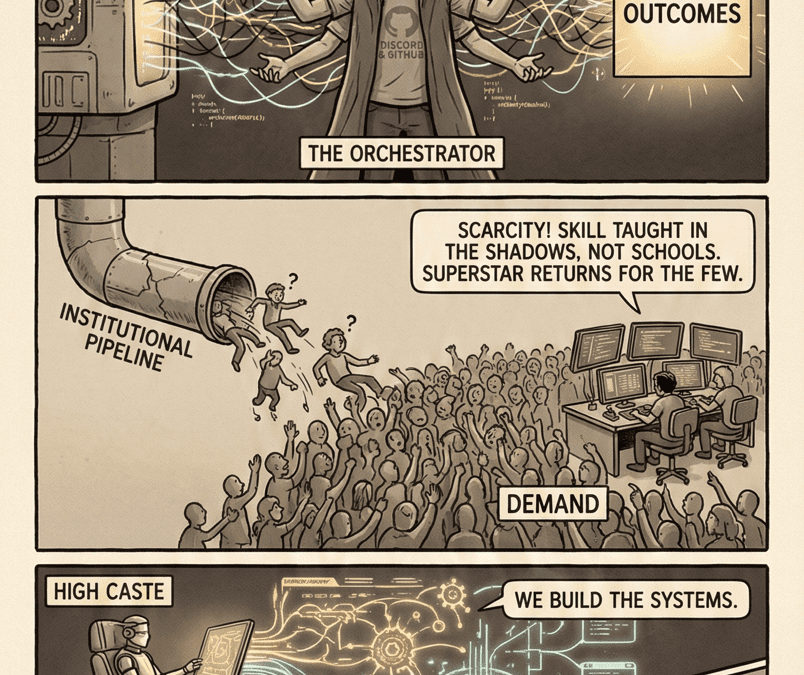
The answer is a class of people who do not yet have a name, a credential, or a union. They have no institutional pipeline. They have no formal training. Their most critical skill is largely illegible to the organizations that depend on them.
This essay is an attempt to name that skill, price that market, and make visible that power. It proposes a framework for understanding who the orchestration class is, why they are essential to any functioning AI system, and why their invisibility is systematically destabilizing to labor markets, capital allocation, and institutional accountability.
It is, in other words, a research agenda.
Part I: The Orchestration Gap
There is a mismatch between AI capability and AI deployment. Not because models are weak, but because the task of translating raw model capability into reliable organizational outcomes remains profoundly human.
Consider a concrete workflow: A large language model is tasked with analyzing legal discovery documents for relevance to a specific case. Naively, this looks automatable. The model reads documents, scores them, and returns a list. Done.
In practice, the work is 5% model inference and 95% everything else.
Someone must:
- Define what “relevance” means in the specific context of this case (ontology design)
- Curate training examples that teach the model what counts as relevant (data annotation and curation)
- Evaluate whether the model’s scoring aligns with human judgment (validation)
- Debug false positives and false negatives (triage)
- Adjust thresholds and constraints based on downstream consequences (control)
- Explain to stakeholders why certain decisions were made (accountability)
- Track performance over time and signal when performance degrades (monitoring)
Each of these activities requires judgment. Judgment cannot be automated. It requires people.
These people are the orchestration class. And they are invisible in almost all labor market data, occupational classification, firm org charts, and AI capability discussions.
Part II: Why Orchestration Is Unpriced
The orchestration class’s economic invisibility is not accidental. It follows from how AI capabilities are marketed, priced, and perceived.
AI vendors explicitly market models as “autonomous.” The pitch is that the model will “replace” a role. The model will “reduce headcount.” The model is a substitute for human labor, not a complement to it.
This framing is convenient for vendors because it simplifies pricing. You buy a model. You deploy it. You reduce headcount by X. Your ROI is straightforward: salary savings divided by API costs.
But this framing is misleading. What you are actually buying is a platform that requires a new class of labor to operate effectively. That labor is not included in the vendor’s pricing model. It is externalized to the customer.
As a result, orchestration work accumulates in firm balance sheets as unpriced overhead. It is not a line item. It is not budgeted. It is not professional. It has no credential, no career path, and no union.
This creates a systematic underpricing of AI deployment costs and a systematic overestimation of AI’s displacement impact.
Part III: The Skills of Orchestration
What, specifically, does the orchestration class know that cannot be automated?
1. Illegible Domain Judgment
The most critical orchestration skill is the ability to translate between model behavior and organizational goals in contexts where the mapping is contested, ambiguous, or evolving. A lawyer knows what “responsibly handling contradictory case law” means. A machine learning engineer knows how to parameterize it. An orchestration worker knows how to align the two when they diverge—and they always diverge.
This skill is not teachable in the traditional sense. It requires:
- Deep familiarity with the domain (law, medicine, accounting)
- Technical literacy without formal training (knowing what a model can and cannot do)
- Comfort with iterative ambiguity (not everything has a right answer)
- The ability to hold contradictory truths in tension
2. Failure Mode Detection
ML models fail in ways humans do not. A lawyer might miss a case for familiar reasons. A model will miss it for reasons nobody predicted. Orchestration workers develop an intuition for where models break, how to stress-test them, and when to reject their outputs as untrustworthy.
This is pattern recognition. It cannot be encoded in a rule. It emerges from experience.
3. Accountability Translation
When an AI system makes a decision with consequences—a loan denial, a medical recommendation, a hiring rejection—someone is legally responsible. In most current systems, that responsibility is diffused across the vendor, the firm, and the model itself. Orchestration workers navigate this ambiguity and make it concrete. They log decisions. They document reasoning. They create audit trails. They prepare for liability.
4. Market Signal Interpretation
Orchestration workers are often the first to detect when a model’s outputs have stopped aligning with real-world conditions. A model trained on historical hiring data might continue recommending candidates who never succeed in your specific firm. Orchestration workers notice performance drift before it becomes catastrophic. They signal when retraining is necessary. They know which signals matter and which are noise.
Part IV: The Market Cannot Price Orchestration
Orchestration labor will not be priced efficiently by labor markets because:
1. Demand is hidden. Firms are not explicitly hiring for “orchestration.” They are redistributing existing staff into role combinations. Finance analysts become model validators. Product managers become feature designers for oversight systems. Lawyers become training-data curators. The demand is real but invisible in ONET, BLS, or firm org charts.
2. Supply is constrained. There is no credential, no degree program, no certification. The only way to develop these skills is to have been in a role that required them. You cannot hire for orchestration directly from school. You can only promote into it.
3. Skill definition is fluid. The skill set is evolving faster than occupational categories can track. An orchestration worker in 2025 knows how to manage GPT-4 outputs. In 2026, the skill shifts to managing multi-agent systems. In 2027, perhaps it shifts to handling autonomous agents with real-world consequences. The skill is not stable enough to be credentialed or reliably taught.
4. Vendor incentives misalign with market transparency. AI vendors have strong incentives to market models as “autonomous” and to understate orchestration costs. This creates systematic bias in how firms estimate true deployment costs, and therefore in how much they are willing to pay for orchestration labor.
The result is severe underpricing of the most critical skill in AI systems: the ability to make them work at organizational scale.
Part V: The Orchestration Class as the Final Labor Bottleneck
This matters for the larger post-labor narrative because the orchestration class is likely the true bottleneck on AI adoption at scale.
The post-labor thesis predicts that AI capability will expand until human labor is unnecessary. But this analysis assumes that firms can simply deploy models and extract value. If orchestration labor is the binding constraint, then labor is not becoming unnecessary—it is being concentrated in a new role that cannot be automated, and the quantity of that labor determines the maximum speed of AI adoption.
Consider the numbers: Assume each deployed AI system requires 1-3 FTE of continuous orchestration work (curation, monitoring, validation, control). If firms are deploying 1 million new AI systems per year (and they are), that implies a demand for 1-3 million orchestration workers per year. The current supply is approximately zero, measured by any occupational category.
This creates a hard supply constraint. Unless orchestration skills can be dramatically compressed or automated (and current evidence suggests they cannot), then the scaling of AI adoption is bounded by the labor supply of orchestration workers, not by model capability.
The post-labor thesis misses this constraint because it asks “Can models do the work?” rather than asking “Can models do the work *and* the oversight work needed to make the work trustworthy?”
The second question has a different answer. And it keeps labor in the system at the precise moment models are supposed to render it obsolete.
Part VI: Research Directions
To actually measure and understand the orchestration class, research needs to address:
- Occupational reclassification: Which existing roles are becoming orchestration work? How fast is this recomposition happening?
- Skill demand measurement: How much orchestration labor does each deployed AI system actually require? Does this vary by domain, by model type, by firm size?
- Compensation analysis: Are orchestration workers being paid as if they are doing valuable, scarce work? Or are they being compensated as routine overhead?
- Bottleneck timing: At what point does orchestration labor supply become the binding constraint on AI adoption in a given sector?
- Automation potential: What subset of orchestration tasks is actually automatable? Can oversight itself be systematized?
Conclusion: The Visibility Problem
The orchestration class exists. They are working in every firm deploying serious AI systems. They are essential. They are invisible.
This invisibility has consequences. It biases forecasts of AI’s displacement impact. It misallocates capital (firms underestimate true deployment costs). It prevents institutional adaptation (there is no credential, no union, no professional identity). It creates compensation arbitrage (orchestration workers are paid below their scarcity value because their scarcity is unrecognized).
And it keeps labor in the system precisely when the post-labor narrative assumes it will exit.
The research agenda is to make the orchestration class visible, to measure their actual market demand, to understand what skills cannot be compressed, and to forecast how this constraint will shape AI adoption curves over the next decade.
Until we do, any argument about the future of work is missing a structural piece of the puzzle.
This essay is part of the research foundation for The Theory of Recursive Displacement — a unified framework examining how AI-driven automation reshapes labor markets, capital flows, governance structures, and human economic agency. Read the full theory for the complete analysis.
Ask questions about this content?
I'm here to help clarify anything